 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKECRS: Towards Knowledge-Enriched Conversational Recommendation System
May 18, 2021
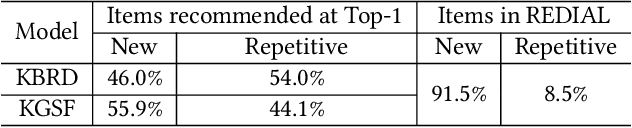
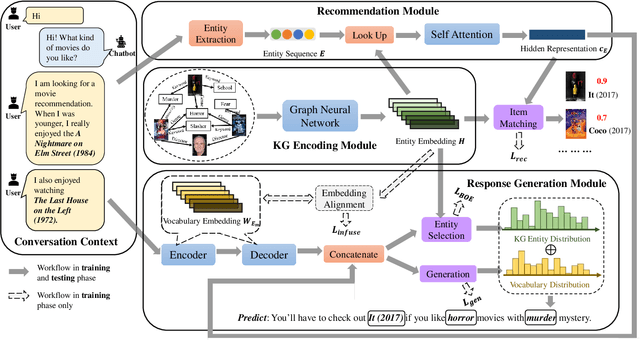
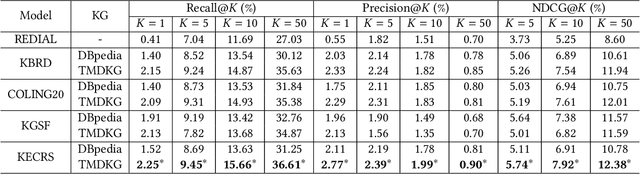
The chit-chat-based conversational recommendation systems (CRS) provide item recommendations to users through natural language interactions. To better understand user's intentions, external knowledge graphs (KG) have been introduced into chit-chat-based CRS. However, existing chit-chat-based CRS usually generate repetitive item recommendations, and they cannot properly infuse knowledge from KG into CRS to generate informative responses. To remedy these issues, we first reformulate the conversational recommendation task to highlight that the recommended items should be new and possibly interested by users. Then, we propose the Knowledge-Enriched Conversational Recommendation System (KECRS). Specifically, we develop the Bag-of-Entity (BOE) loss and the infusion loss to better integrate KG with CRS for generating more diverse and informative responses. BOE loss provides an additional supervision signal to guide CRS to learn from both human-written utterances and KG. Infusion loss bridges the gap between the word embeddings and entity embeddings by minimizing distances of the same words in these two embeddings. Moreover, we facilitate our study by constructing a high-quality KG, \ie The Movie Domain Knowledge Graph (TMDKG). Experimental results on a large-scale dataset demonstrate that KECRS outperforms state-of-the-art chit-chat-based CRS, in terms of both recommendation accuracy and response generation quality.
Keyword-Guided Neural Conversational Model
Dec 27, 2020
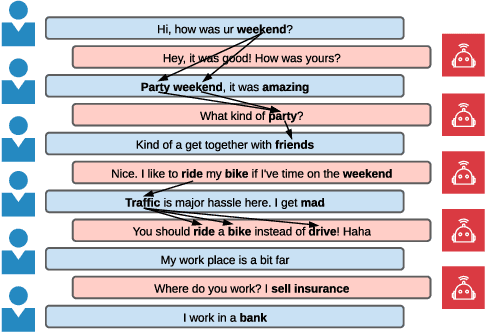

We study the problem of imposing conversational goals/keywords on open-domain conversational agents, where the agent is required to lead the conversation to a target keyword smoothly and fast. Solving this problem enables the application of conversational agents in many real-world scenarios, e.g., recommendation and psychotherapy. The dominant paradigm for tackling this problem is to 1) train a next-turn keyword classifier, and 2) train a keyword-augmented response retrieval model. However, existing approaches in this paradigm have two limitations: 1) the training and evaluation datasets for next-turn keyword classification are directly extracted from conversations without human annotations, thus, they are noisy and have low correlation with human judgements, and 2) during keyword transition, the agents solely rely on the similarities between word embeddings to move closer to the target keyword, which may not reflect how humans converse. In this paper, we assume that human conversations are grounded on commonsense and propose a keyword-guided neural conversational model that can leverage external commonsense knowledge graphs (CKG) for both keyword transition and response retrieval. Automatic evaluations suggest that commonsense improves the performance of both next-turn keyword prediction and keyword-augmented response retrieval. In addition, both self-play and human evaluations show that our model produces responses with smoother keyword transition and reaches the target keyword faster than competitive baselines.
CARE: Commonsense-Aware Emotional Response Generation with Latent Concepts
Dec 15, 2020
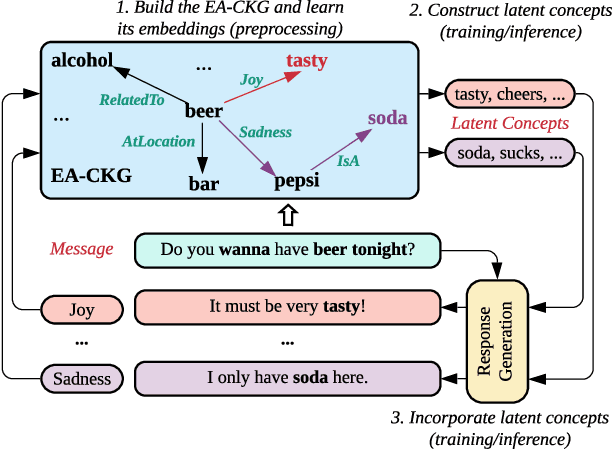

Rationality and emotion are two fundamental elements of humans. Endowing agents with rationality and emotion has been one of the major milestones in AI. However, in the field of conversational AI, most existing models only specialize in one aspect and neglect the other, which often leads to dull or unrelated responses. In this paper, we hypothesize that combining rationality and emotion into conversational agents can improve response quality. To test the hypothesis, we focus on one fundamental aspect of rationality, i.e., commonsense, and propose CARE, a novel model for commonsense-aware emotional response generation. Specifically, we first propose a framework to learn and construct commonsense-aware emotional latent concepts of the response given an input message and a desired emotion. We then propose three methods to collaboratively incorporate the latent concepts into response generation. Experimental results on two large-scale datasets support our hypothesis and show that our model can produce more accurate and commonsense-aware emotional responses and achieve better human ratings than state-of-the-art models that only specialize in one aspect.
Endowing Empathetic Dialogue Systems with Personas
Apr 30, 2020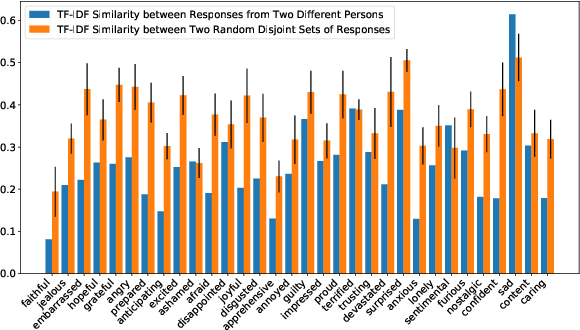
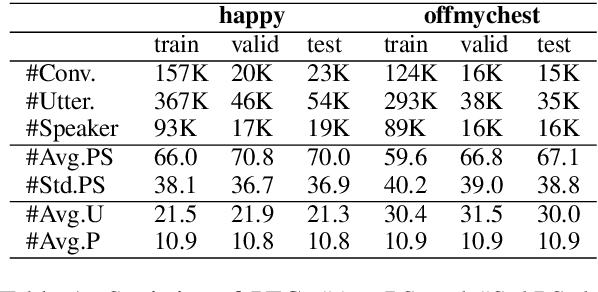
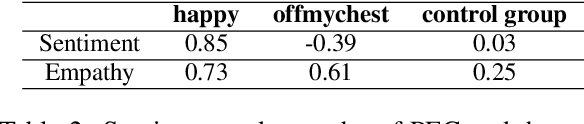
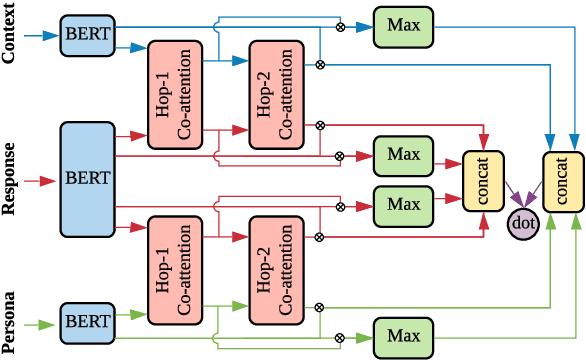
Empathetic dialogue systems have been shown to improve user satisfaction and task outcomes in numerous domains. In Psychology, persona has been shown to be highly correlated to personality, which in turn influences empathy. In addition, our empirical analysis also suggests that persona plays an important role in empathetic dialogues. To this end, we propose a new task to endow empathetic dialogue systems with personas and present the first empirical study on the impacts of persona on empathetic responding. Specifically, we first present a novel large-scale multi-domain dataset for empathetic dialogues with personas. We then propose CoBERT, an efficient BERT-based response selection model that obtains the state-of-the-art performance on our dataset. Finally, we conduct extensive experiments to investigate the impacts of persona on empathetic responding. Notably, our results show that persona improves empathetic responding more when CoBERT is trained on empathetic dialogues than non-empathetic ones, establishing an empirical link between persona and empathy in human dialogues.
Knowledge-Enriched Transformer for Emotion Detection in Textual Conversations
Oct 01, 2019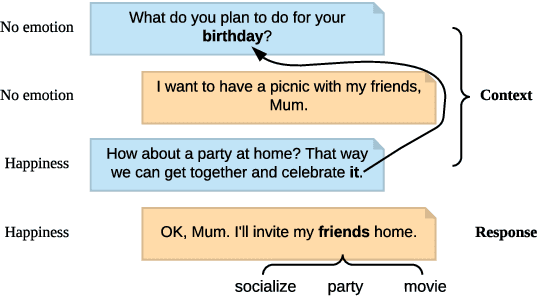

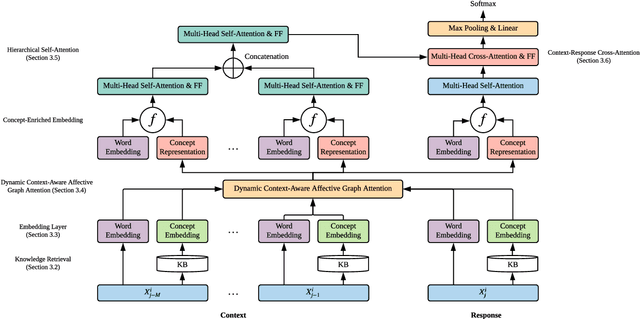
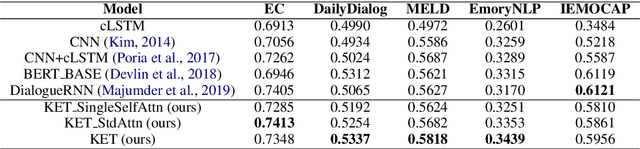
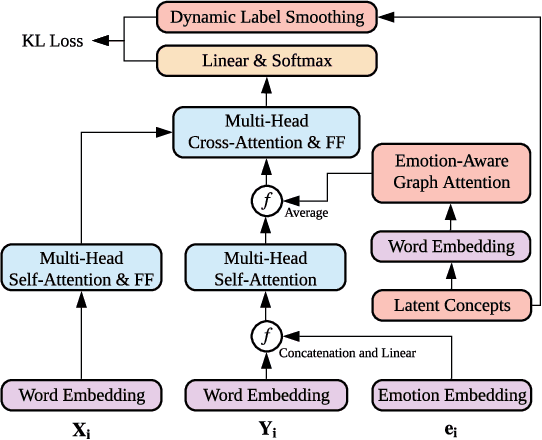
Messages in human conversations inherently convey emotions. The task of detecting emotions in textual conversations leads to a wide range of applications such as opinion mining in social networks. However, enabling machines to analyze emotions in conversations is challenging, partly because humans often rely on the context and commonsense knowledge to express emotions. In this paper, we address these challenges by proposing a Knowledge-Enriched Transformer (KET), where contextual utterances are interpreted using hierarchical self-attention and external commonsense knowledge is dynamically leveraged using a context-aware affective graph attention mechanism. Experiments on multiple textual conversation datasets demonstrate that both context and commonsense knowledge are consistently beneficial to the emotion detection performance. In addition, the experimental results show that our KET model outperforms the state-of-the-art models on most of the tested datasets in F1 score.
EEG-Based Emotion Recognition Using Regularized Graph Neural Networks
Aug 26, 2019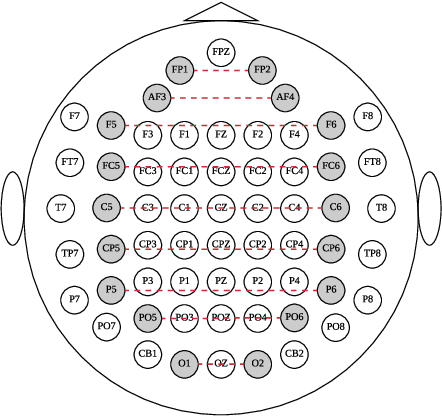
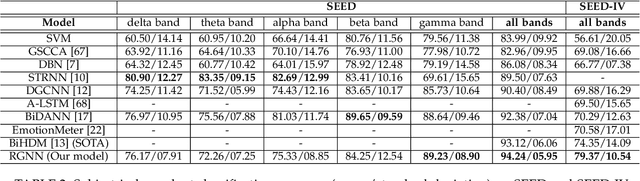
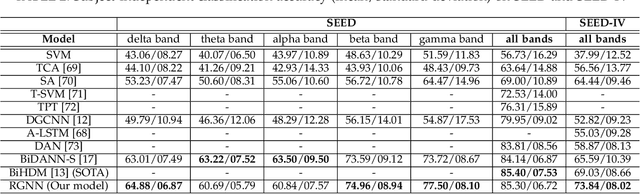
EEG signals measure the neuronal activities on different brain regions via electrodes. Many existing studies on EEG-based emotion recognition do not exploit the topological structure of EEG signals. In this paper, we propose a regularized graph neural network (RGNN) for EEG-based emotion recognition, which is biologically supported and captures both local and global inter-channel relations. Specifically, we model the inter-channel relations in EEG signals via an adjacency matrix in our graph neural network where the connection and sparseness of the adjacency matrix are supported by the neurosicience theories of human brain organization. In addition, we propose two regularizers, namely node-wise domain adversarial training (NodeDAT) and emotion-aware distribution learning (EmotionDL), to improve the robustness of our model against cross-subject EEG variations and noisy labels, respectively. To thoroughly evaluate our model, we conduct extensive experiments in both subject-dependent and subject-independent classification settings on two public datasets: SEED and SEED-IV. Our model obtains better performance than competitive baselines such as SVM, DBN, DGCNN, BiDANN, and the state-of-the-art BiHDM in most experimental settings . Our model analysis demonstrates that the proposed biologically supported adjacency matrix and two regularizers contribute consistent and significant gain to the performance. Investigations on the neuronal activities reveal that pre-frontal, parietal and occipital regions may be the most informative regions for emotion recognition, which is consistent with relevant prior studies. In addition, experimental results suggest that global inter-channel relations between the left and right hemispheres are important for emotion recognition and local inter-channel relations between (FP1, AF3), (F6, F8) and (FP2, AF4) may also provide useful information.
ntuer at SemEval-2019 Task 3: Emotion Classification with Word and Sentence Representations in RCNN
Apr 02, 2019
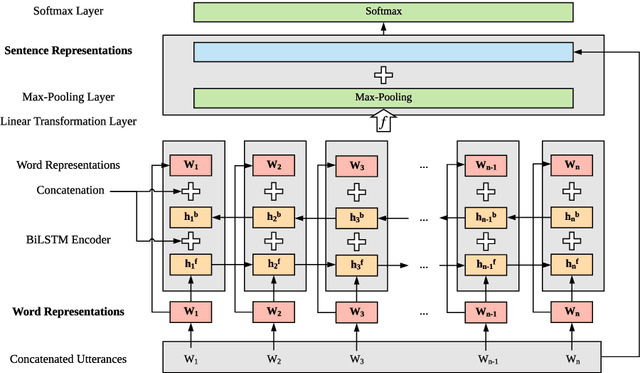
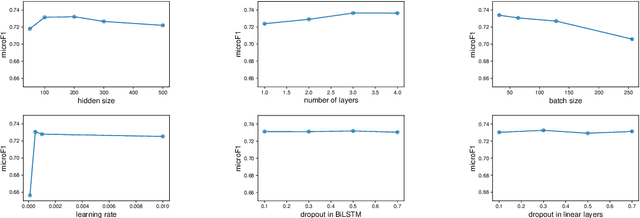
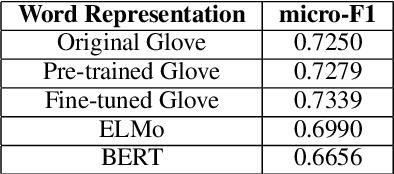
In this paper we present our model on the task of emotion detection in textual conversations in SemEval-2019. Our model extends the Recurrent Convolutional Neural Network (RCNN) by using external fine-tuned word representations and DeepMoji sentence representations. We also explored several other competitive pre-trained word and sentence representations including ELMo, BERT and InferSent but found inferior performance. In addition, we conducted extensive sensitivity analysis, which empirically shows that our model is relatively robust to hyper-parameters. Our model requires no handcrafted features or emotion lexicons but achieved good performance with a micro-F1 score of 0.7463.
An Affect-Rich Neural Conversational Model with Biased Attention and Weighted Cross-Entropy Loss
Nov 17, 2018

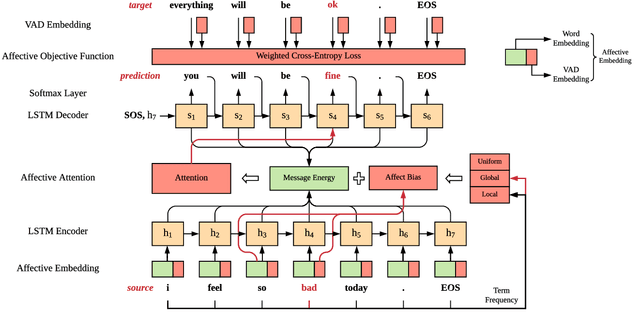
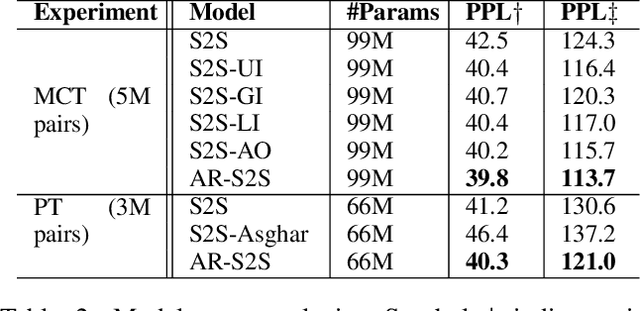
Affect conveys important implicit information in human communication. Having the capability to correctly express affect during human-machine conversations is one of the major milestones in artificial intelligence. In recent years, extensive research on open-domain neural conversational models has been conducted. However, embedding affect into such models is still under explored. In this paper, we propose an end-to-end affect-rich open-domain neural conversational model that produces responses not only appropriate in syntax and semantics, but also with rich affect. Our model extends the Seq2Seq model and adopts VAD (Valence, Arousal and Dominance) affective notations to embed each word with affects. In addition, our model considers the effect of negators and intensifiers via a novel affective attention mechanism, which biases attention towards affect-rich words in input sentences. Lastly, we train our model with an affect-incorporated objective function to encourage the generation of affect-rich words in the output responses. Evaluations based on both perplexity and human evaluations show that our model outperforms the state-of-the-art baseline model of comparable size in producing natural and affect-rich responses.